システムコールだけ使って素朴すぎるHTTPクライアント/サーバーをGoで実装した
実装してみた。素朴すぎてタイムアウトの設定もできないし自動でヘッダーを付与してくれる機能もない。IPv6にも対応してない。
github.comシステムコールだけでHTTP、TCP、UDPクライアント作ってみた。 https://t.co/9JzWUAuEf1
— Kohei Kimura (@cohhei) 2020年2月1日
[追記]クライアントだけでなくサーバーも実装できるようにした。公式のnet/httpのようにHandleFuncとListenAndServeでサーバーが立ち上がる。開発関連のまとめツイートは↓
Implemented an http server by using only system calls.
— Kohei Kimura (@cohhei) 2020年2月8日
システムコールだけで作るhttpサーバーできたhttps://t.co/mmV5kchMfb pic.twitter.com/N0C987TCzG
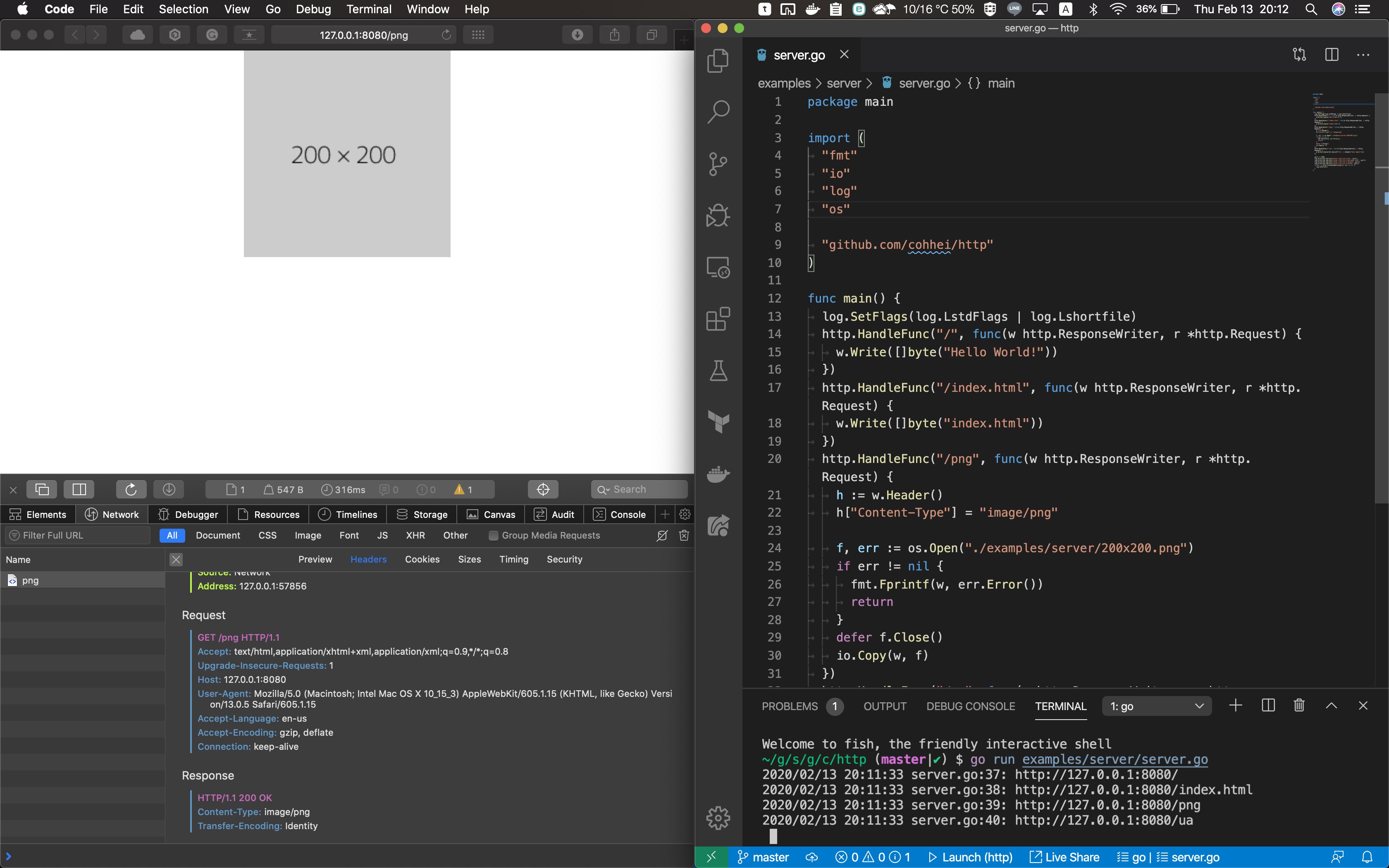
net/httpと同じようなインターフェースで使えるtr;dr
- ネットワークに苦手意識があったので勉強しはじめた。
- 勉強のためにシステムコールを直接使ってTCP通信を行うHTTPクライアントとTCPクライアントを作ってみた。
- ついでにUDPクライアントも作った。
- HTTPサーバーも作った。
- カーネルすごい。インターネットすごい。
Go の strings パッケージを読んでみる
Go の標準パッケージのコードを読んでみる。まずは読みやすそうな strings パッケージ からはじめてみる。
Homebrew で Go をインストールしている場合は /usr/local/opt/go/libexec/src/ にコードがあるはずなのでまずはエディタで開く。現在のバージョンは 1.11.2。
$ go version go version go1.11.2 darwin/amd64 $ code /usr/local/opt/go/libexec/src/続きを読む

語学学習のための時間を確保してはいけない
この記事はプログラマのための英語・外国語 Advent Calendar 2017 - Qiitaの17日目のあれです。
続きを読む