ストリーム処理で文章内にある単語の出現頻度をカウントする(Apache Apex) その2 -コーディング編-
ストリーム処理で文章内にある単語の出現頻度をカウントする(Apache Apex) - 駄文型 の続き。前回は環境構築や実行のみを行い、サンプルコードの中身までは触れていない。そこで今回はサンプルコードを読み解き、 Apex ストリーミングアプリケーション開発の雰囲気を掴んでいく。
概要
サンプルコードのファイルは以下の7つ。
- ApplicationWordCount.java
- LineReader.java
- WordReader.java
- WindowWordCount.java
- FileWordCount.java
- WordCountWriter.java
- WCPair.java
参考
ApplicationWordCount
まずはアプリケーション本体。やっていることは単純で、オペレーターを作成し、それらをストリームで繋いで DAG を作っているだけ。
package com.example.myapexapp; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.datatorrent.api.annotation.ApplicationAnnotation; import com.datatorrent.api.StreamingApplication; import com.datatorrent.api.DAG; import org.apache.hadoop.conf.Configuration; @ApplicationAnnotation(name="SortedWordCount") public class ApplicationWordCount implements StreamingApplication { private static final Logger LOG = LoggerFactory.getLogger(ApplicationWordCount.class); @Override public void populateDAG(DAG dag, Configuration conf) { // create operators LineReader lineReader = dag.addOperator("lineReader", new LineReader()); WordReader wordReader = dag.addOperator("wordReader", new WordReader()); WindowWordCount windowWordCount = dag.addOperator("windowWordCount", new WindowWordCount()); FileWordCount fileWordCount = dag.addOperator("fileWordCount", new FileWordCount()); WordCountWriter wcWriter = dag.addOperator("wcWriter", new WordCountWriter()); // create streams dag.addStream("lines", lineReader.output, wordReader.input); dag.addStream("control", lineReader.control, fileWordCount.control); dag.addStream("words", wordReader.output, windowWordCount.input); dag.addStream("windowWordCounts", windowWordCount.output, fileWordCount.input); dag.addStream("fileWordCounts", fileWordCount.fileOutput, wcWriter.input); } }
@ApplicationAnnotation(name="SortedWordCount") でアプリケーション名を設定できる。これは前回実行時に出てきた名称と一致する。
apex> launch target/myapexapp-1.0-SNAPSHOT.apa 1. MyFirstApplication 2. SortedWordCount # これ Choose application: 2 {"appId": "application_1496704660177_0001"} apex (application_1496704660177_0001) >
各オペレーターとストリームの関係を図示すると下の図のようになる。ほぼ一直線だが、 lineReader から fileWordCount へ control というストリームが飛んでいる。 Apex ではこのようにオペレーターを繋いで DAG をつくりことでアプリケーションを組むことができる。オペレーターの接続点をポートと呼ぶ。
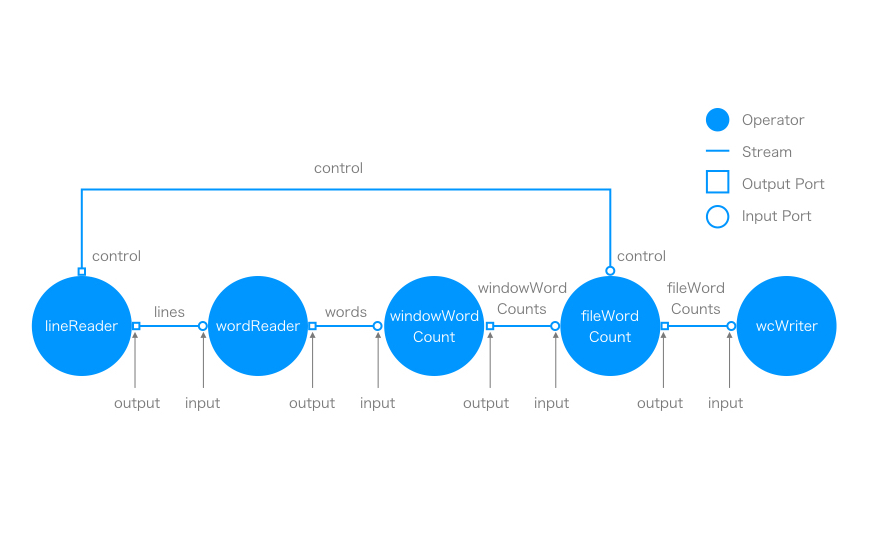
LineReader
先頭 lineReader オペレーターから見ていく。このオペレーターは、ファイルを読み込み、中身を output ポートに流し、ファイルパスを control に流す。
package com.example.myapexapp; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import org.apache.hadoop.fs.Path; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.datatorrent.api.annotation.OutputPortFieldAnnotation; import com.datatorrent.api.DefaultOutputPort; import com.datatorrent.lib.io.fs.AbstractFileInputOperator; // reads lines from input file and returns them; if end-of-file is reached, a control tuple // is emitted on the control port // public class LineReader extends AbstractFileInputOperator<String> { private static final Logger LOG = LoggerFactory.getLogger(LineReader.class); public final transient DefaultOutputPort<String> output = new DefaultOutputPort<>(); @OutputPortFieldAnnotation(optional = true) public final transient DefaultOutputPort<String> control = new DefaultOutputPort<>(); private transient BufferedReader br = null; private Path path; @Override protected InputStream openFile(Path curPath) throws IOException { LOG.info("openFile: curPath = {}", curPath); path = curPath; InputStream is = super.openFile(path); br = new BufferedReader(new InputStreamReader(is)); return is; } @Override protected void closeFile(InputStream is) throws IOException { super.closeFile(is); br.close(); br = null; path = null; } // return empty string @Override protected String readEntity() throws IOException { // try to read a line final String line = br.readLine(); if (null != line) { // common case LOG.debug("readEntity: line = {}", line); return line; } // end-of-file; send control tuple, containing only the last component of the path // (only file name) on control port // if (control.isConnected()) { LOG.info("readEntity: EOF for {}", path); final String name = path.getName(); // final component of path control.emit(name); } return null; } @Override protected void emit(String tuple) { output.emit(tuple); } }
メンバー変数
このオペレータークラスのメンバは以下の5つ。
- LOG: ロガー
- output: アウトプットポート
- control: アウトプットポート
- br: バッファ
- path: ファイルのパス
特に説明は不要だが、 control に対して
@OutputPortFieldAnnotation(optional = true)
というアノテーションが追加されている。オプショナルが true になっている。何故オプショナルにしているのかはよくわからない。わかったら追記します。
メソッド
LineReader では openFile , closeFile , readEntity , emit というメソッドが定義されており、それぞれでファイルを開いた時の処理、閉じたときの処理、開いたファイルから次のタプルを読み込む処理、タプルへの処理を記述している。
readEntitiy では、バッファから1行読み込み、それを返している。 EOF まで読み込み終わったら contorl ポートにファイル名を流し、ストリームを終了させている。戻り値として返したものが次のタプルになり、 emit メソッドで処理される。 null を返すとストリームが終了する。
// return empty string @Override protected String readEntity() throws IOException { // try to read a line final String line = br.readLine(); if (null != line) { // common case LOG.debug("readEntity: line = {}", line); return line; } // end-of-file; send control tuple, containing only the last component of the path // (only file name) on control port // if (control.isConnected()) { LOG.info("readEntity: EOF for {}", path); final String name = path.getName(); // final component of path control.emit(name); } return null; }
WordReader
WordReader は、 LineReader から送られてきた1行分のデータを単語に分割している。
package com.example.myapexapp; import java.util.regex.Pattern; import com.datatorrent.api.Context.OperatorContext; import com.datatorrent.api.DefaultInputPort; import com.datatorrent.api.DefaultOutputPort; import com.datatorrent.common.util.BaseOperator; // extracts words from input line public class WordReader extends BaseOperator { // default pattern for word-separators private static final Pattern nonWordDefault = Pattern.compile("[\\p{Punct}\\s]+"); private String nonWordStr; // configurable regex private transient Pattern nonWord; // compiled regex public final transient DefaultOutputPort<String> output = new DefaultOutputPort<>(); public final transient DefaultInputPort<String> input = new DefaultInputPort<String>() { @Override public void process(String line) { // line; split it into words and emit them final String[] words = nonWord.split(line); for (String word : words) { if (word.isEmpty()) continue; output.emit(word); } } }; public String getNonWordStr() { return nonWordStr; } public void setNonWordStr(String regex) { nonWordStr = regex; } @Override public void setup(OperatorContext context) { if (null == nonWordStr) { nonWord = nonWordDefault; } else { nonWord = Pattern.compile(nonWordStr); } } }
メンバー変数
- nonWordDefault: デフォルトの単語分割パターン
- nonWordStr: 単語分割用の正規表現
- nonWord: 単語分割パターン
- output: アウトプットポート
- input: インプットポート
これもほぼ説明は不要かと思うが、インプットポートはアウトプットポート異なり単に new するだけでなく、なにやら処理が記述されている。
public final transient DefaultInputPort<String> input = new DefaultInputPort<String>() { @Override public void process(String line) { // line; split it into words and emit them final String[] words = nonWord.split(line); for (String word : words) { if (word.isEmpty()) continue; output.emit(word); } } };
インプットポートには、入力されたデータをどう処理するかを記述する。これは他のオペレーターも同様で、 WordReader 以降の FileWordCount までのオペレーターも同様にインプットポートごとに process メソッドが定義されている。ここでは、入力データをパターンで単語に分割して、アウトプットポートに流している。
メソッド
- getNonWordStr
- setNonWordStr
- setup
getNonWordStr と setNonWordStr はただの getter と setter 。 setup はセットアップ時に呼び出され、 nonWord の設定を行っている。
@Override public void setup(OperatorContext context) { if (null == nonWordStr) { nonWord = nonWordDefault; } else { nonWord = Pattern.compile(nonWordStr); } }
WindowWordCount
WindowWordCount は、 WordReader から送られる単語をウィンドウ内で集計して単語と出現頻度のペアにまとめる。
package com.example.myapexapp; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.datatorrent.api.DefaultInputPort; import com.datatorrent.api.DefaultOutputPort; import com.datatorrent.common.util.BaseOperator; // Computes word frequency counts per window and emits them at each endWindow. The output is a // list of pairs (word, frequency). // public class WindowWordCount extends BaseOperator { private static final Logger LOG = LoggerFactory.getLogger(WindowWordCount.class); // wordMap : word => frequency protected Map<String, WCPair> wordMap = new HashMap<>(); public final transient DefaultInputPort<String> input = new DefaultInputPort<String>() { @Override public void process(String word) { WCPair pair = wordMap.get(word); if (null != pair) { // word seen previously pair.freq += 1; return; } // new word pair = new WCPair(); pair.word = word; pair.freq = 1; wordMap.put(word, pair); } }; // output port which emits the list of word frequencies for current window // fileName => list of (word, freq) pairs // public final transient DefaultOutputPort<List<WCPair>> output = new DefaultOutputPort<>(); @Override public void endWindow() { LOG.info("WindowWordCount: endWindow"); // got EOF; if no words found, do nothing if (wordMap.isEmpty()) return; // have some words; emit single map and reset for next file final ArrayList<WCPair> list = new ArrayList<>(wordMap.values()); output.emit(list); list.clear(); wordMap.clear(); } }
メンバー変数
- LOG: ロガー
- wordMap: 単語と出現頻度のペアをマップにまとめたもの
- input: インプットポート
- output: アウトプットポート
wordMap 単語と頻度のペアは WCPair として WCPair.java で定義されている。
package com.example.myapexapp; // a single (word, frequency) pair public class WCPair { public String word; public int freq; public WCPair() {} public WCPair(String w, int f) { word = w; freq = f; } @Override public String toString() { return String.format("(%s, %d)", word, freq); } }
input の中身を見ていく。 WordReader の出力は1単語なので、入力は単語がひとつになる。入力された単語を wordMap から探索し、存在していれば頻度に1を加算し、存在していなければ新たに WCPair を作成してマップに追加する。
public final transient DefaultInputPort<String> input = new DefaultInputPort<String>() { @Override public void process(String word) { WCPair pair = wordMap.get(word); if (null != pair) { // word seen previously pair.freq += 1; return; } // new word pair = new WCPair(); pair.word = word; pair.freq = 1; wordMap.put(word, pair); } };
メソッド
メソッドは endWindow のみです。このメソッドは、ウィンドウが終了したときに呼び出される。マップをリストにしてアウトプットポートに流している。ウィンドウの設定をしていないようなので、デフォルト値があると思われるが、デフォルト値がなんなのかよくわからない。わかったら追記しておきます。
public void endWindow() { LOG.info("WindowWordCount: endWindow"); // got EOF; if no words found, do nothing if (wordMap.isEmpty()) return; // have some words; emit single map and reset for next file final ArrayList<WCPair> list = new ArrayList<>(wordMap.values()); output.emit(list); list.clear(); wordMap.clear(); }
FileWordCount
FileWordCount はファイル全体から単語の出現頻度を集計する。
public class FileWordCount extends BaseOperator { private static final Logger LOG = LoggerFactory.getLogger(FileWordCount.class); // set to true when we get an EOF control tuple protected boolean eof = false; // last component of path (i.e. only file name) // incoming value from control tuple protected String fileName; // wordMapFile : {word => frequency} map, current file, all words protected Map<String, WCPair> wordMapFile = new HashMap<>(); // singleton map of fileName to sorted list of (word, frequency) pairs protected transient Map<String, Object> resultFileFinal; // final sorted list of (word,frequency) pairs protected transient List<WCPair> fileFinalList; public final transient DefaultInputPort<List<WCPair>> input = new DefaultInputPort<List<WCPair>>() { @Override public void process(List<WCPair> list) { // blend incoming list into wordMapFile and wordMapGlobal for (WCPair pair : list) { final String word = pair.word; WCPair filePair = wordMapFile.get(word); if (null != filePair) { // word seen previously in current file filePair.freq += pair.freq; continue; } // new word in current file filePair = new WCPair(word, pair.freq); wordMapFile.put(word, filePair); } } }; public final transient DefaultInputPort<String> control = new DefaultInputPort<String>() { @Override public void process(String msg) { if (msg.isEmpty()) { // sanity check throw new RuntimeException("Empty file path"); } LOG.info("FileWordCount: EOF for {}", msg); fileName = msg; eof = true; // NOTE: current version only supports processing one file at a time. } }; // fileOutput -- tuple is singleton map {<fileName> => fileFinalList}; emitted on EOF public final transient DefaultOutputPort<Map<String, Object>> fileOutput = new DefaultOutputPort<>(); @Override public void setup(OperatorContext context) { // singleton map {<fileName> => fileFinalList}; cannot populate it yet since we need fileName resultFileFinal = new HashMap<>(1); fileFinalList = new ArrayList<>(); } @Override public void endWindow() { LOG.info("FileWordCount: endWindow for {}", fileName); if (wordMapFile.isEmpty()) { // no words found if (eof) { // write empty list to fileOutput port // got EOF, so output empty list to output file fileFinalList.clear(); resultFileFinal.put(fileName, fileFinalList); fileOutput.emit(resultFileFinal); // reset for next file eof = false; fileName = null; resultFileFinal.clear(); } LOG.info("FileWordCount: endWindow for {}, no words", fileName); return; } LOG.info("FileWordCount: endWindow for {}, wordMapFile.size = {}, eof = {}", fileName, wordMapFile.size(), eof); if (eof) { // got EOF earlier if (null == fileName) { // need file name to emit topN pairs to file writer throw new RuntimeException("EOF but no fileName at endWindow"); } // sort list from wordMapFile into fileFinalList and emit it getList(wordMapFile); resultFileFinal.put(fileName, fileFinalList); fileOutput.emit(resultFileFinal); // reset for next file eof = false; fileName = null; wordMapFile.clear(); resultFileFinal.clear(); } } // populate fileFinalList with topN frequencies from argument // This list is suitable input to WordCountWriter which writes it to a file // MUST have map.size() > 0 here // private void getList(final Map<String, WCPair> map) { fileFinalList.clear(); fileFinalList.addAll(map.values()); // sort entries in descending order of frequency Collections.sort(fileFinalList, new Comparator<WCPair>() { @Override public int compare(WCPair o1, WCPair o2) { return (int)(o2.freq - o1.freq); } }); LOG.info("FileWordCount:getList: fileFinalList.size = {}", fileFinalList.size()); } }
メンバー変数
- LOG: ロガー
- eof: ファイルの読み込み終わりフラグ
- fileName: ファイル名
- wordMapFile: ファイル単位での単語の出現頻度
- resultFileFinal: 集計結果を格納するマップ
- fileFinalList: 集計結果を格納するリスト
- input: インプットポート
- control: インプットポート、ファイル名
- fileOutput: アウトプットポート
input を見ていく。 WindowWordCount とほぼ同じで、単語の出現頻度を集計してマップに入れている。
public final transient DefaultInputPort<List<WCPair>> input = new DefaultInputPort<List<WCPair>>() { @Override public void process(List<WCPair> list) { // blend incoming list into wordMapFile and wordMapGlobal for (WCPair pair : list) { final String word = pair.word; WCPair filePair = wordMapFile.get(word); if (null != filePair) { // word seen previously in current file filePair.freq += pair.freq; continue; } // new word in current file filePair = new WCPair(word, pair.freq); wordMapFile.put(word, filePair); } } };
次に control 。 lineReader からファイル名が流れてくるので、それを保存して eof フラグを ON に。
public final transient DefaultInputPort<String> control = new DefaultInputPort<String>() { @Override public void process(String msg) { if (msg.isEmpty()) { // sanity check throw new RuntimeException("Empty file path"); } LOG.info("FileWordCount: EOF for {}", msg); fileName = msg; eof = true; // NOTE: current version only supports processing one file at a time. } };
メソッド
setup はマップとリストの初期化を行っているだけなので省略。
endWindow を見ていく。少々長いが、やっていることは単純で、ウィンドウが終わったタイミングで eof が ON になっている(つまりファイルの読み込みが終わっている)場合、集計結果をアウトプットポートに流す。流すときに getList でソートなどの加工を行っている。
public void endWindow() { LOG.info("FileWordCount: endWindow for {}", fileName); if (wordMapFile.isEmpty()) { // no words found if (eof) { // write empty list to fileOutput port // got EOF, so output empty list to output file fileFinalList.clear(); resultFileFinal.put(fileName, fileFinalList); fileOutput.emit(resultFileFinal); // reset for next file eof = false; fileName = null; resultFileFinal.clear(); } LOG.info("FileWordCount: endWindow for {}, no words", fileName); return; } LOG.info("FileWordCount: endWindow for {}, wordMapFile.size = {}, eof = {}", fileName, wordMapFile.size(), eof); if (eof) { // got EOF earlier if (null == fileName) { // need file name to emit topN pairs to file writer throw new RuntimeException("EOF but no fileName at endWindow"); } // sort list from wordMapFile into fileFinalList and emit it getList(wordMapFile); resultFileFinal.put(fileName, fileFinalList); fileOutput.emit(resultFileFinal); // reset for next file eof = false; fileName = null; wordMapFile.clear(); resultFileFinal.clear(); } } private void getList(final Map<String, WCPair> map) { fileFinalList.clear(); fileFinalList.addAll(map.values()); // sort entries in descending order of frequency Collections.sort(fileFinalList, new Comparator<WCPair>() { @Override public int compare(WCPair o1, WCPair o2) { return (int)(o2.freq - o1.freq); } }); LOG.info("FileWordCount:getList: fileFinalList.size = {}", fileFinalList.size()); }
WordCountWriter
最後は WordCountWriter 。集計結果をファイルに出力するオペレーター。こちらは今までとは異なり、 AbstractFileOutputOperator を継承しているので、少々実装が違っている。
public class WordCountWriter extends AbstractFileOutputOperator<Map<String, Object>> { private static final Logger LOG = LoggerFactory.getLogger(WordCountWriter.class); private static final String charsetName = "UTF-8"; private static final String nl = System.lineSeparator(); private String fileName; // current file name private transient final StringBuilder sb = new StringBuilder(); @Override public void endWindow() { if (null != fileName) { requestFinalize(fileName); } super.endWindow(); } // input is a singleton list [M] where M is a singleton map {fileName => L} where L is a // list of pairs: (word, frequency) // @Override protected String getFileName(Map<String, Object> tuple) { LOG.info("getFileName: tuple.size = {}", tuple.size()); final Map.Entry<String, Object> entry = tuple.entrySet().iterator().next(); fileName = entry.getKey(); LOG.info("getFileName: fileName = {}", fileName); return fileName; } @Override protected byte[] getBytesForTuple(Map<String, Object> tuple) { LOG.info("getBytesForTuple: tuple.size = {}", tuple.size()); // get first and only pair; key is the fileName and is ignored here final Map.Entry<String, Object> entry = tuple.entrySet().iterator().next(); final List<WCPair> list = (List<WCPair>) entry.getValue(); if (sb.length() > 0) { // clear buffer sb.delete(0, sb.length()); } for ( WCPair pair : list ) { sb.append(pair.word); sb.append(" : "); sb.append(pair.freq); sb.append(nl); } final String data = sb.toString(); LOG.info("getBytesForTuple: data = {}", data); try { final byte[] result = data.getBytes(charsetName); return result; } catch (UnsupportedEncodingException ex) { throw new RuntimeException("Should never get here", ex); } } }
メンバー変数
- LOG: ロガー
- charsetName: エンコード
- nl: 改行コード
- fileName: ファイル名
- sb: StringBuilder
メソッド
endWindow では、 requestFinalize を呼び出してファイル処理を終了する。
public void endWindow() { if (null != fileName) { requestFinalize(fileName); } super.endWindow(); }
getFileName には、ファイル名の取得方法を記述。
protected String getFileName(Map<String, Object> tuple) { LOG.info("getFileName: tuple.size = {}", tuple.size()); final Map.Entry<String, Object> entry = tuple.entrySet().iterator().next(); fileName = entry.getKey(); LOG.info("getFileName: fileName = {}", fileName); return fileName; }
getBytesForTuple では、タプルからファイルに出力する内容を記述する。ここではリストを整形して一つの文字列にして返している。
protected byte[] getBytesForTuple(Map<String, Object> tuple) { LOG.info("getBytesForTuple: tuple.size = {}", tuple.size()); // get first and only pair; key is the fileName and is ignored here final Map.Entry<String, Object> entry = tuple.entrySet().iterator().next(); final List<WCPair> list = (List<WCPair>) entry.getValue(); if (sb.length() > 0) { // clear buffer sb.delete(0, sb.length()); } for ( WCPair pair : list ) { sb.append(pair.word); sb.append(" : "); sb.append(pair.freq); sb.append(nl); } final String data = sb.toString(); LOG.info("getBytesForTuple: data = {}", data); try { final byte[] result = data.getBytes(charsetName); return result; } catch (UnsupportedEncodingException ex) { throw new RuntimeException("Should never get here", ex); } }
まとめ
Apex ではまずアプリケーション全体をオペレーターの DAG で設計する。 DAG の構成が決まったら各オペレーターの処理を記述するだけ。他のストリーム処理エンジンに詳しくないので、比較はできないが、分散処理をあまり意識しなくていいので書きやすそう。また、よく使われそうな処理は Malhar にライブラリとして準備されているため、簡単に書くことができる。